TeamCity Performance Tuning
Kurzinfo zu den Ergebnissen aus unserer Analyse und zur neuen Systemarchitektur
Continuous Integration (CI) Server und ihre angeschlossenen Systeme bilden oft den Kern von Softwareproduktionsumgebungen. Die Steuerung der Buildprozesse, die Prüfung der Checkins, Start und Auswertung der Testverfahren zählen zu den wichtigsten Aufgaben.
Mit JetBrains TeamCity als CI-Server hatte sich folgende Struktur in unserer Entwicklungsabteilung etabliert.

Mit der ständigen Zunahme an Projekten und Aufgaben die der CI-Server übernahm, sank auch systematisch seine Performance. Langsam aber kontinuierlich verlängerten sich die Bedienabläufe der Oberfläche und auch die Masken zur Auswahl der Checkin Goals (Pre-Tested Comit) in der Entwicklungsoberfläche IntelliJ IDEA brauchten viel zu lange beim Öffnen (ca. 20 Sekunden).
Um das Problem zu lösen haben wir eine TeamCity Taskforce gegründet. Ziel war die Suche und die Behebung der Ursachen für den Performanceverlust des CI-Servers.
Bestandsaufnahme
Um den Performanceverlust möglichst exakt zu bewerten, brauchten wir ein Meßverfahren, welches möglichst schnell eine Aussage zur Wirkung einer Konfigurationsänderung machte. Da die Kommunikation zwischen der Entwicklungsoberfläche und dem CI-Server via XML durchgeführt wird, haben wir versucht die langlaufenden Requests zu extrahieren und durch einen Batchaufruf (curl) für die Kommandozeile tauglich gemacht.
anfrage.xml:
<?xml version="1.0"?>
<methodCall>
<methodName>RemoteBuildServer2.getRegisteredProjects</methodName>
<params>
<param>
<value>
<boolean>1</boolean>
</value>
</param>
</params>
</methodCall>
send.sh:
curl -b "$Version=0; JSESSIONID=123.worker12; $Path=/teamCity;xmlrpcsessionId=123"
-H "Content-Type: text/xml; charset=utf-8"
-X POST -d @anfrage.xml http://teamcity.hypoport.local/teamCity/RPC2
analyseLauf.sh:
while :; do
time ./send.sh >>ergebnisse_zweiter_lauf.txt 2>>ergebnisse_stderr.txt;
sleep 20;
done
Damit konnte das Systemverhalten gemessen und graphisch dargestellt werden.
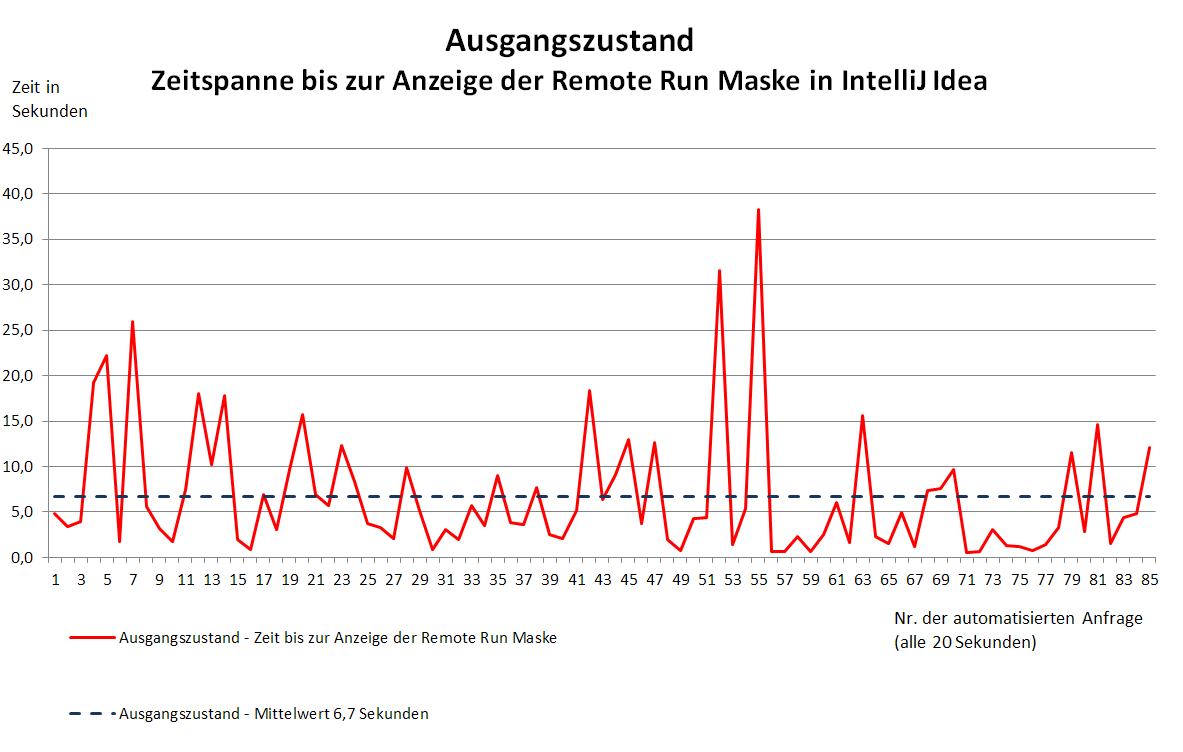
Um Änderungen ohne Auswirkungen auf das Produktivsystem zu prüfen, wurde eine Kopie des virtuellen CI-Servers und der MySQL Datenhaltung angelegt. Die eigentliche Analysearbeit konnte nun beginnen. Dabei standen diese Arbeitsschritte im Vordergrund.
- Logfileanalyse und Konfiguration des Loggings Logmeldungen wurden mehrfach ausgegeben (log4j, Konfig), Logfiles waren sehr groß, mehrere GB
- Tcpdump, Wireshark zur Trafficanalyse zwischen CI-Server und - VCS (SVN, GIT)
- Buildagents
- Arbeitsstationen
- Windows Domainserver (Nutzeranmeldung)
- Analyse Traffic und Prozeßsteuerung zwischen Apache Httpd, mod_jk und Apache Tomcat
- Analyse Resourcenverbrauch der Prozesse mit Betriebssystemwerkzeuge (iostat, vmstat, sar, ps, top) sowie der JConsole
- Tool jstack zur automatischen Erstellung von Threaddumps
- Tomcat-Filter und Valves zur Analyse und Prüfung der Request/Response Inhalte
- Diagnosefunktionen im TeamCity Managementserver zur Messung des Performanceverhaltens der VCS-Roots
Maßnahmen
Nach der Aufnahme der Daten versuchten wir eine Aussage auf die Auswirkung einer Einzeländerung z.B. Parametrierung MySQL Cache, auf das Gesamtverhalten zu treffen.
Dabei kam immer wieder das Testprogramm mit der Simulation der Kommunikation zwischen IDEA und TeamCity zum Einsatz. Viele Iterationen und Prüfläufe liesen uns dann folgende Maßnahmen als Sinnvoll erachten.
- Abschaltung des vorgelagerten Apache Httpd
- Einsatz der Apache Tomcat APR Library
- MySQL Optimierungen (Cache, Export, Import, Wartung, aggressiver Cleanup)
- GIT Zugriff via GIT-Protokoll anstatt SSH
- Optimierung des JVM Memory Sizings
- Nächtliches Housekeeping pro Server (Stop, Automatische Logfileanalyse, Cleanup, Start)
- Verbesserung der ICinga, Nagios Systemmonitorings unserer Entwicklungsinfrastruktur
- Einsatz von TeamCity 7 mit integriertem Servletcontainer
- Arbeitstreffen mit JetBRAINS zur Optimierung und Klärung von Fragen
Kompatibel für die Nutzer bleiben
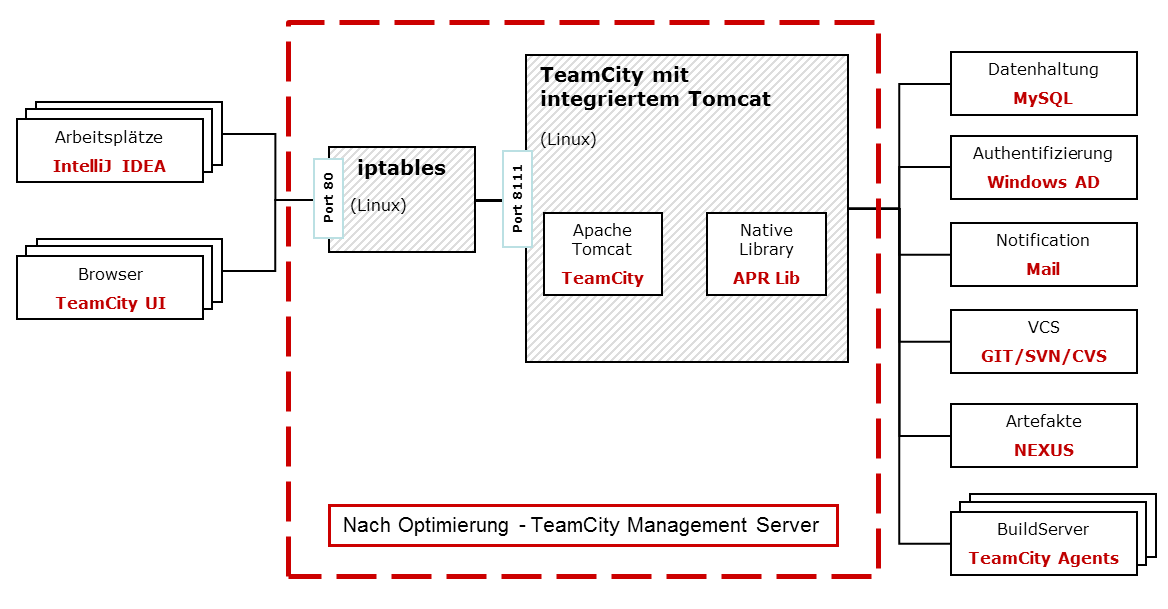
Durch den wegfallenden Apache Httpd Server und unserem Wunsch nach Kompatiblität der Zugriff-Urls musste noch eine Teilaufgabe gelöst werden. Da die TeamCity Anwendung nicht mit Administrationsrechten läuft, darf sie keine TCP Port Bindung gegen Ports unterhalb 1024 durchführen.
Die Lösung für dieses Teilproblem bestand im Einsatz einer entsprechenden Konfiguration für den iptables Filter. Dieser Filter leitet die auf Port 80 einlaufenden Requests gegen den TeamCity Port 8111 weiter. Analog wurden mit den Ports für https Verbindungen verfahren.
/etc/sysconfig/iptables:
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
COMMIT
*nat
:PREROUTING ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A PREROUTING -d 192.168.99.10 -i eth0 -p tcp -m tcp –dport 80 -j REDIRECT –to-ports 8111
-A PREROUTING -d 192.168.99.10 -i eth0 -p tcp -m tcp –dport 443 -j REDIRECT –to-ports 8543
-A OUTPUT -d 192.168.99.10 -p tcp -m tcp –dport 443 -j REDIRECT –to-ports 8543
-A OUTPUT -d 192.168.99.10 -p tcp -m tcp –dport 80 -j REDIRECT –to-ports 8111
COMMIT
Auswertungen
Durch die Arbeiten und Optimierungen konnten wir die Antwortzeiten deutlich beschleunigen. So sank die durchschnittliche Antwortzeit von 6.7 Sekunden auf 0.3 Sekunden. Die neue Struktur und Version antwortete etwa um den Faktor 22 mal schneller.
Die neue Systemübersicht ist in der folgenden Abbildung dargestellt. TeamCity wird dabei auf Basis des TAR.GZ Installationspaketes betrieben.
Vergleicht man die Ergebnisse mit dem Systemverhalten vor der Optimierung
 so konnten die Wartezeiten für Entwickler beim Checkin von 20 Sekunden auf unter 1 Sekunde gesenkt werden.
so konnten die Wartezeiten für Entwickler beim Checkin von 20 Sekunden auf unter 1 Sekunde gesenkt werden.
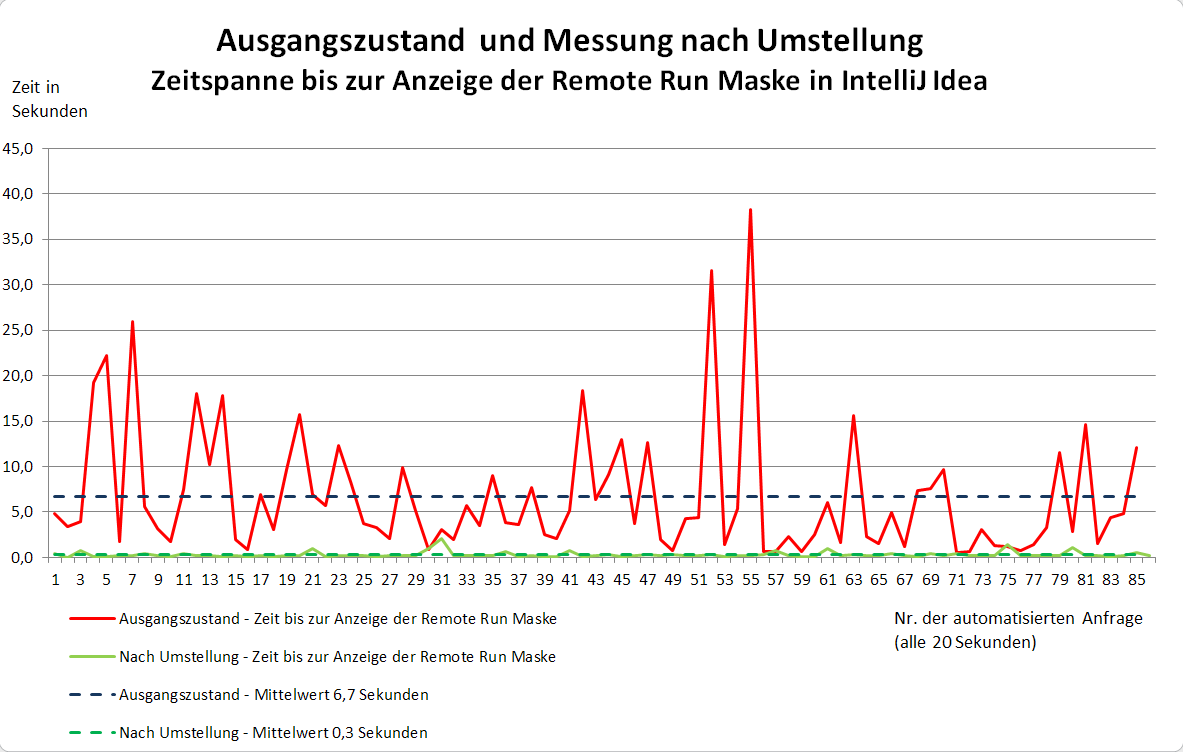 Das Antwortzeitverhalten der Webapplikation profitierte ebenfalls von den Maßnahmen.
Das Antwortzeitverhalten der Webapplikation profitierte ebenfalls von den Maßnahmen.
Zusammenarbeit der Teams vom Development und Operations
Möglich wurden diese Ergebnisse durch eine intensive Zusammenarbeit der Teams von Operations und aus der Softwareentwicklung.
Für uns ist dieser Stelle auch noch nicht Schluß, weil die vielen gemeinsamen Analysen aus der Bestandsaufnahme noch einiges an ToDo Listen übrig gelassen haben. Die neu gegründete DevOps-Community verfolgt diese Themen nun weiter.