
TL;DR: Wir haben Baufinanzierungsunterlagen automatisch mit einem Machine Learning Algorithmus klassifiziert und dabei mit einem einfachen, linearen Algorithmus sehr gute Ergebnisse erzielt.
Wer ein Darlehen für ein Haus beantragen will, muss einen nicht geringen Stapel an Unterlagen zusammen sammeln und bei dem Kreditanbieter einreichen. Diese Unterlagen müssen in der Regel noch von Hand klassifiziert, überprüft und sortiert werden und obwohl die Unterlagen heutzutage schon häufig elektronisch eingereicht werden, ist es tatsächlich nicht unüblich, das eine PDF gedruckt wird, von Hand sortiert und dann wieder eingescannt wird. Diesen Prozess wollten wir vereinfachen und verbessern (und nebenbei vielleicht ein paar Bäumen das Leben retten?). Hierzu wollten wir ein Modell entwickeln, das automatisch erkennt, welche Unterlagen in einer PDF enthalten sind.
Auf dem Exploration Day, eine Art interner Hackathon, den wir bei Europace regelmäßig veranstalten, haben wir uns zusammengesetzt und versucht einen Algorithmus zusammen zu hacken, der Unterlagen klassifiziert. Da man auf einem Hackathon nur begrenzt Zeit hat, war unser erstes Ziel einen einfachen Klassifizierer zu bauen, der überhaupt erstmal funktioniert. Nach dem Motto komplizierter geht später auch noch. Die Unterlagen lagen uns dabei als Scan vor, aus denen wir mit hilfe eines OCR-Tools (wir haben Tesseract von Google benutzt) den Text extrahiert haben. Die daher resultierenden Textdateien haben wir als Datengrundlage für unser Modell genommen. Zum Preprocessing der Texte haben wir die tf-idf Methode benutzt, die sich am einfachsten an einem Beispiel erklären lässt:
Nehmen wir an Unterlage 1 und 2 enthalten jeweils die folgende Sätze:
- Ich erteile der Bank die Vollmacht, meine Verbindlichkeiten bei der Beispiel Bank abzulösen.
- Der Bausparvertrag unserer Bank bietet Ihnen eine besonders günstige Finanzierung.
In einer Liste sammeln wir alle Wörter, die in in den Unterlagen vorkommen:
[Ich, erteile, der, Bank, die, Vollmacht, meine, Verbindlichkeiten, bei, Beispiel, abzulösen, Bausparvertrag, unserer, bietet, Ihnen, eine, besonders, günstige, Finanzierung]
Für jede Unterlage wird dann gezählt, wie häufig welche Wörter vorkommen und diese Word counts in einen Vector geschrieben:
[1,1,2,2,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0]
[0,0,1,1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1]
Da die Wörter, die in allen Unterlagen vorkommen (“der”), wenig Informationen über den Unterlagentyp enthalten, sollen diese Wörter niedrig gewichtet und Wörter, die nur in spezifischen Unterlagenklassen vorkommen (z.B. “Verbindlichkeiten”) und daher mehr Informationen enthalten, höher gewichtet werden. Dafür wird die Termfrequenz TF und die inverse Dokumentfrequenz IDF miteinander multipliziert:
TF(w,D)= Anzahl der Vorkommen des Wortes w in dem Dokument D (die Word Counts)IDF(w)= 1/Anzahl der Vorkommen des Wortes w in dem Dokument D
Das heißt, wenn 20% aller Dokumente das Wort “Bausparen” enthalten, dann ist
IDF(“Bausparen”) = 1/0.2 = 5
Wohingegen die IDF für “der”, enthalten in 97% aller Dokumente dann
IDF(“der”) = 1/0.97 = 1.03
ist. Daraus berechnet sich dann die TF-IDF:
TF-IDF(w,D) = TF(w,D) * IDF(w)
So erhalten wir zu jeder Unterlage einen Vektor mit gewichteten Wordcounts, die wir dann in eine Support Vector Machine (SVM) gespeist haben. Eine SVM versucht Punkte (hier unser Wordcount Vektoren) verschiedener Klassen durch eine Trennlinie mit maximalem Abstand zu trennen:
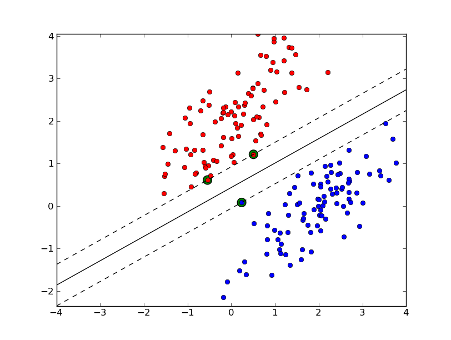
Dieses relativ simple Model hat uns eine so gute Erkennungsrate geliefert, dass wir uns entschieden haben, dieses Projekt über den Hackathon hinaus zu verfolgen. Das Erfolg des sehr einfachen, linearen Modells hat uns außerdem darin bestätigt, dass es wichtig ist, immer mit dem einfachsten, simpelsten Modells anzufangen (“Always start with a stupid model”). Dies hat uns nicht nur davor bewahrt viele Stunden Arbeit in ein unnötig komplexes Modell zu stecken, dass durch seine Komplexität auch höhere Wartungsarbeiten mit sich bringt, sondern ein simpleres Modell ermöglicht auch eine einfachere Interpretation der Ergebnisse und an welchen Punkten es sich lohnt mehr Komplexität reinzubringen. Beispielsweise ist unser Modell nicht sehr gut darin Unterlagen mit wenig Text zu erkennen (wie etwa Objektfotos). Daher konzentrieren wir uns nun darauf diese Unterlagen mit komplexeren Methoden besser zu klassifizieren.