
TL;DR
Er kommt meist überraschend, führt zu sprunghaftem Ansteigen des Adrenalinspiegels und alle Beteiligten sind froh, wenn er vorüber ist - der Incident. Wie wir bei EUROPACE mit ihm umgehen und wie wir aus ihm lernen.
Houston - wir haben ein Problem
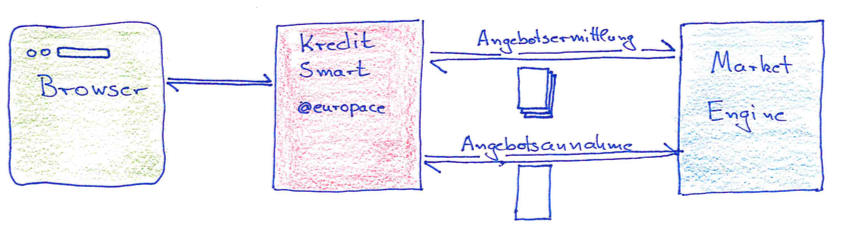
Am 21.11.2017 war KreditSmart (ein Teilsystem der EUROPACE-Plattform) für etwa 2 Stunden nur sehr eingeschränkt benutzbar. Eine der Kernfunktionalitäten - die Ermittlung von Privatkreditangeboten - war für mehrere tausend Vermittler nicht verfügbar.
Ein Vermittler vermisste die sonst zügig angezeigte Angebotsliste. Zufällig saß einer unserer Entwickler an diesem Tag in seiner Nähe, so dass der Vermittler ihm persönlich Bescheid geben konnte, statt ein Zendesk-Ticket zu erstellen. Der Entwickler zögerte nicht lange und meldete es in unseren Slack-Incident-Channel.
Aufgrund der Incident-Benachrichtigung trafen sich fünf Entwickler/Operator in einem Appear.in Video-Chat, um den Incident zu bewerten und zu beheben.
Überblick verschaffen
KreditSmart ist aus einzelnen Microservices aufgebaut - so war schnell klar, welche Services gesund sind und welche Stress hatten. Mit Hilfe unseres Prometheus-basierten Monitoring-Systems identifizierten wir, welche Funktionen/Subsysteme unserer Plattform betroffen waren.
Kein System ist fehlerfrei - das gilt auch für KreditSmart. KreditSmart wird von vielen Vermittlern für ihre tägliche Arbeit genutzt und daher sind wir bestrebt auftretende Fehler schnell zu beheben. Dazu gehört für uns auch Transparenz zu schaffen und auf bestehende Probleme auf unserer Statusseite hinzuweisen.
Fix durch Restart
Die Analyse hatte drei Services in den Fokus gerückt, die vermutlich mit dem Problem in Zusammenhang standen. Wir starteten diese nacheinander durch. Nach dem Neustart des dritten Services verhielt sich die Angebotsermittlung wieder annährend normal und wir meldeten den Incident als gelöst. Lucky!
Analyse
Im Nachgang machten wir ein Analyse, um herauszufinden, was eigentlich passiert war.
Uns fiel auf, dass wir eine Diskrepanz der Antwortzeiten der Angebotsermittlungen fanden - wurden sie in KreditSmart gemessen waren sie zum Teil drastisch höher als in der Market Engine.
Das Studium des Codes sowie der bereits verfügbaren Metriken zwischen den Services brachte uns zunächst nicht weiter, so dass wir weitere Logs einbauten.
Nachdem diese kurze Zeit später deployed waren, stellten wir keine Diskrepanz mehr zwischen den gemessenen Zeiten fest.
Was war geschehen? Bei der Erweiterung des Loggings hatten wir eine kleine unscheinbare Veränderung in der Konfiguration der Verbindung zur Market Engine vorgenommen, die offenbar zur Auflösung des Problems führte.
Nach weiterer Analyse stellten wir fest, dass die Konfiguration die gleichzeitigen Verbindungen zur Market Engine zu stark begrenzte. Bisher teilten sich die schnellen Angebotsermittlungen (<1 Sekunde) einen Verbindungspool mit den langsameren Angebotsannahmen (>1 Minute). Durch einen starken Anstieg der Vermittlerzahlen, die wir an dem Tag des Incidents verzeichneten, kam es dazu, dass erstmals so viele Angebotsannahmen zeitgleich aktiv waren, dass dadurch keine Angebotsermittlungen mehr bearbeitet werden konnten. Die Angebotsermittlungen liefen in einen Timeout und daher wurden in der Angebotsliste keine Angebote mehr angezeigt.
Post Mortem
Nach einem Incident setzen sich bei uns die Beteiligten nochmals zusammen, um in Ruhe zu überlegen, was passiert war und was wir daraus lernen können. In einem solchem Post-Mortem geht es also nicht darum einen Schuldigen zu finden, sondern etwas daraus zu lernen, damit wir in der Zukunft besser werden.
Unter anderem war eine Erkenntnis, dass wir den Incident nicht, wie sonst oft, durch unser umfangreiches Monitoring selbst bemerkt haben - für dieses Problem war es leider blind. Als Action-Item haben wir das Schließen dieser Lücke identifiziert - dies wurde zeitnah umgesetzt und so erkennen wir nun drohende, verstopfte Verbindungen bevor diese zu einem Incident führen.
Nach der Analyse war es bereits offensichtlich: Die Anzahl der parallelen Verbindungen war zu klein - das oben eingeführte Monitoring lieferte uns die Zahlen, wie sich unser System im Normalzustand verhält - entsprechend haben wir die Anzahl der parallelen Verbindungen angepasst (und werden sie auch zukünftig bei z.B. Lastanstieg anpassen).