In part four of our series about our continuous deployment pipeline you’ll learn about how we perform contract tests to ensure our service stays compatible with other service producers and our consumers as well.
Please read the introductury post to learn about the other articles and the overall context of our deployment pipeline.
This article contains both an introduction to contract testing, and our individual implementation of contract testers. If you’re new to the contract testing concept, just read on. If you’re already familiar to the overall concept and want to start with our code, you can skip to the Contract Test Orchestration section.
What are Contract Tests?
The comprehensive overview on Testing Strategies in a Microservice Architecture introduces contract testing as complementary method to increase test coverage:
Apart from unit, integration, component, and end-to-end tests, the contract tests aim at checking service boundaries.
Every consumer defines a set of criteria or requirements which need to be fulfilled by a service producer. The sum of all requirements defines the overall service contract. With contract testing, consumers can check the producer’s contract or their own requirements before a new release is deployed in production.
The contract tests shouldn’t check the producer’s behaviour, but only verify that the API can be consumed. Checking behaviour would result in component tests, which should be performed on the producer’s side and are not the responsibility of its consumers.
Contract tests should be performed either when the consumer changes or when the producer changes. While it should be easy for every consumer to perform their own contract tests, they should also provide a test package for the producer’s pipeline or environment. That way the producer can preview its own changes and their effect on every consumer.
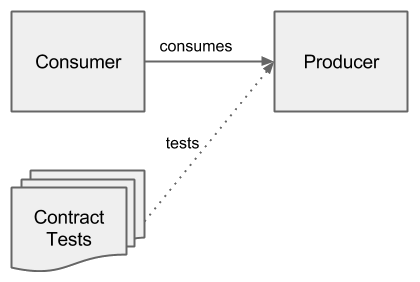
The figure above shows an overview for a combination of consumer, producer and contract tests. Contract tests are shown as tests from the consumer’s perspective.
Contract Tests in Real Life
As easy as it sounds, performing contract tests in continuous deployment pipelines isn’t trivial.
In our case services are written in Java, so we write our contract tests as Java unit tests, using test runners like JUnit or TestNG and execute them with shell or Gradle scripts. Packaging such test classes as jar files and publishing them in an artifact repository belongs to the simple aspects. But making a producer available for contract tests can become very exciting and produces several questions, e.g.:
- can the tests be performed against the production service?
- what happens when tests need some setup (e.g. a user account) or need to have a valid session to consume the service API?
- do the tests have an effect on the overall service availablility?
- what about database entries being generated by the tests – do we need a cleanup?
With both consumer and producer in one team communication becomes easier when concepts or requirements are introduced or changed. When consumer and producer are split between different teams or even companies, it becomes more important to define a clear API. Consumer-Driven Contracts help the producer to align their implementation at the consumer’s needs.
To address the questions above, the producer might avoid to let all consumers perform tests against the production service – unless they want to stress test theim. Often, the producer has a staging concept, with a mirror to production system being available for different kind of tests. Such systems should behave as much as possible like the production system. An alternative to a dedicated test stage are services being started spontaneously, and only for the actual test run. Such systems should boot very fast to support a fast feedback cycle and increase the developers‘ acceptance.
Sometimes neither test stages nor ad hoc services are possible. Then one can change the production behaviour dependent on the logged in user role or based on request parameters. Nevertheless, the producer should still try to support the consumer writing tests independent on producer specific issues: request parameters to only toggle a under test behaviour on the producer side would become a part of the contract test – and ultimately a part of the contract. Changing the producer’s test setup would then break the contract tests, though the API as test subject could stay the same.
The questions above show that runtime dependencies on a database can make things complicated. Similarly to the options we have with services, databases can also be provided via staging, but can also be started as needed. Starting a database spontaneously often implies that they can be thrown away quite easily, so one doesn’t need to care about cleanups.
Contract Tests in a CI Environment
In our team we have several combinations of our services being consumer of other services at our company and also being a producer for other services. Our contract test setup isn’t limited to our own pipeline, but the other involved services need to perform the contract tests in their pipelines, too.
Contract tests can be triggered either when the producer or when the consumer changes. In case any tests fail, the newly built service shouldn’t be deployed to production. Since APIs evolve over time, the contract tests also change over time, so that they always match a combination of the consumer and producer version. The combination needs to be considered in the pipelines of the consumer and the producer as well:
- When our service as consumer changes, we need to perform our contract tests against all producers whose API we consume. We need to perform the tests against the productive version of the producers, because we’d like to ensure that our newly built consumer will be working on our production system together with the producers‘ services.
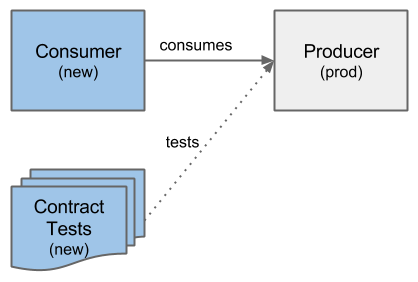
- When a producer changes, it should trigger our contract tests to run against their newly built service. It should choose those tests which match our service in the production environment.
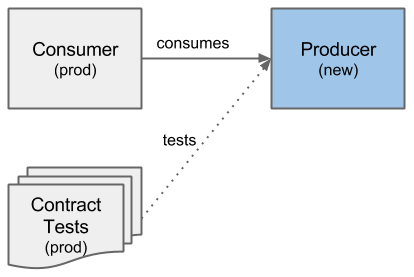
Both combinations are shown in very similar figures, where only service versions are changed (in blue), but the overall concept stays the same.
Contract Test Orchestration
We didn’t explain how a producer can find and execute the consumer’s contract tests. We also didn’t explain how a consumer can ask for a testable producer in cases where the production service shouldn’t be used. In our case, we try to run a producer on demand, but sometimes we needed to use staged services of other teams.
To solve those orchestrating aspects, we introduced specific contract tester projects. Over time, we added a specific contract tester for every combination of consumer and producer in our responsibility. Both sides of a contract test need to collaborate so that neither of them is enforced to know too many details on how to run a service or perform the contract tests. In our case we started with both consumer and producer being developed in our team, so that we didn’t differentiate between both sides very much.
Initial Contract Tester Implementation
Our first iteration of a contract tester had cross cutting knowledge about consumer and producer, so that we combined all necessary tasks in one Gradle script. To ease the use of the contract tester, we added two tasks which are considered as entrypoints for the producer’s and the consumer’s pipelines, respectively. Only one of both tasks should be run at a time, with the entrypoints named like:
- performContracttestsTriggeredBy_Consumer_
- performContracttestsTriggeredBy_Producer_
Dependent on which of both tasks is run, the contract tester uses the productive or the newly built version of consumer and producer. So, running the performContracttestsTriggeredByConsumer task results in the following steps:
- resolve the productive version of a producer
- download or pull the productive producer
- download the consumer’s contract tests of the newly built version
- run the producer
- perform the contract tests
- tear down the producer and cleanup
Running the performContracttestsTriggeredByProducer only changes the first three steps:
- resolve the productive version of a consumer
- download or pull the newly built producer
- download the consumer’s contract tests of the productive version
- …
You’ll recognize that only the consumer’s and the producer’s version are input values. We use the TeamCity Artifact Dependencies feature to pass versions of newly built artifacts to the contract test build. The productive versions need to be resolved in a way the service allows us to. Sometimes we can perform a simple HTTP GET on a dedicated URL, sometimes a „resolve“ only means to select a stage (dev or prod) where a service is always running.
A stripped down implementation of our initial contract tester implementation if available at GitHub. The example contract tests validate that the GitHub status API can be consumed. Though we won’t discuss the actual code here, feel free to give it a try and if you have problems running it with the example-project, please ask.
Current Contract Tester Implementation
While the first implementation is still being used and has already been copied for other combinations of producer and consumer, we recently had to provide one of our services as producer to a consuming service of another team. The other team already had their own contract testing concept with their own „Consumer Driven Test Suite“. Our contract tester didn’t need to know how to fetch and perform the contract tests anymore, it only needed to prepare a testable producer service.
We could now consider the consumer as an external service and agree on a clear definition of responsibilities. The common point was the CI-Server TeamCity with our individual pipelines, where both teams needed to add a contract test build goal. Build goals in TeamCity can perform several steps, in our case similarly to a unit test:
- setup/prepare
- run/perform
- tear down/cleanup
The image below shows an overview of our build steps. In the blue box (setup) and as cleanup (tear down) you’ll see the tasks which are implemented for the producing service. The red box (run) shows the task which actually performs the contract tests of the consuming service. Please see the „contracttester-new“ subfolder for the actual code.

The details in the blue box show how we setup our service. Since we use a Docker based setup, our database CouchDB and our service are available as Docker images and can be pulled from a private registry. Both CouchDB and service images have tags, which allow us to fetch the desired version to be run. Both images are used on our production server so that we can be quite sure that the service behaves like in production. The difference to the production environment are mocks for external services, which shouldn’t be relevant for contract tests.
After running the CouchDB and our service, we collect the actual service URL and save it on the TeamCity agent in a well known properties file (named url.properties in the green box of the image). The properties file will then be used in the TeamCity run step as input parameter to the contract tests so that they can reach the producer service without hard coding any URL.
Running the tests in this case is simplified by executing a TestNG runner with the contract tests and their dependencies on the classpath, which happens externally to our contract tester.
The cleanup task is very easy with a Docker based setup: we only need to stop and remove the Docker containers. That way we don’t even need to think about any database changes, because the database container is thrown away after every successful test run, too.
Gradle goodies
In addition to the contract tester concept, we used some more advanced Gradle features. Gradle isn’t only a wrapper around Groovy, but it also tries enable you to use a more build domain specific language in your script files. We’ll only show you some codepointers to the improvements of our most recent contract tester compared to the first iteration.
Build Sources
Gradle knows about a special directory buildSrc, which will be compiled (and tested) before running the build.gradle script. Classes in the buildSrc module will be available in the build script classpath, which allows us to move implementation details to a plugin like submodule.
In our example contract tester, you’ll see that we moved a ProducerVersionResolver and a HealthCheckService to the build source module. Both classes are used in the build script, the former one to find the correct service version, the latter one helps us waiting for the service startup before leaving control back to the caller (i.e. TeamCity).
You can consider the build source module like a minimal plugin implementation without the hazzle of publishing one. The Gradle user guide about organizing build logic discusses the pros and cons of custom tasks, build source, and dedicated plugins and we would recommend you to read it when you’re interested in keeping your build.gradle clear and readable.
Task Rules
In the contract tester we again provided special tasks as entrypoints to the contract tester. This time we didn’t explicitly define both tasks, but used Gradle Task Rules to gain more flexibility and generate the necessary entrypoint on demand. The ./gradlew tasks command lists such rules in the Rules section:
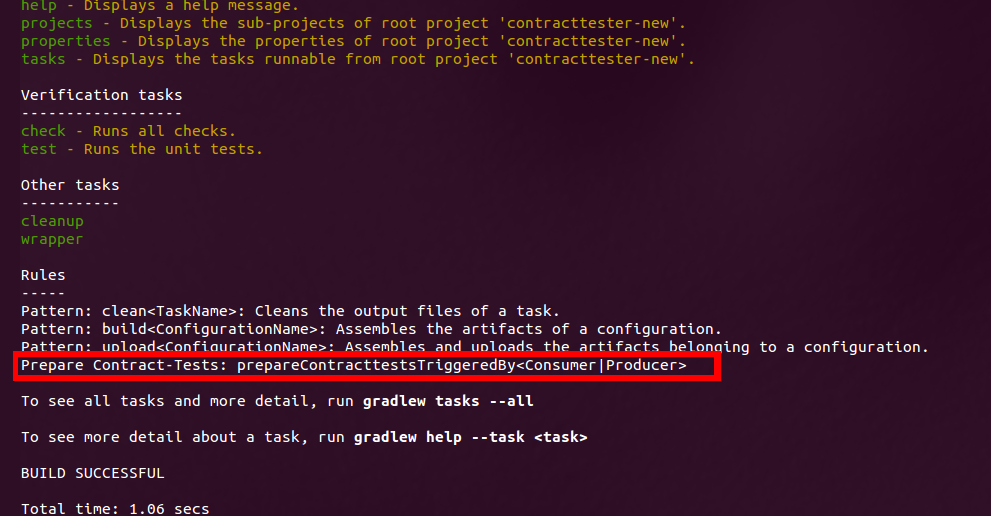
Gradle task rules behave similar to normal tasks, so that they can be called like e.g. ./gradlew prepareContracttestsTriggeredByProducer. Adding such rules is quite simple, you only need to define a closure to handle newly added task names. Our handler dynamically adds dependent on the called task name a new task and configures it to wait for the running producer and finishes with saving the mentioned url.properties file.
Splitting .gradle Scripts
Similar to the build sources directory we tried to clean up our build.gradle by extracting some tasks to other .gradle files. Combined with the task rules, this also enabled us to dynamically apply only necessary files.
The build-setup-producer.gradle contains everything we need to run a producer service and is quite self contained, so that we might reuse the same file for other scenarios.
Dependent on which pipeline triggered our contract tester, we apply anotherbuild-triggered-by-....gradle script. It only determines the service version using the version resolver class and configures the runProducerContainer task to use the desired version.
Applying other .gradle files sadly does’t behave like a simple include, so that we need to keep some little tweaks in mind. One example is the usage of plugins and how to apply them: you cannot use their plugin id, but have to apply their main class. Nevertheless, splitting the main build.gradle script makes sense, when it comes to readability and reuse.
Summary and Outlook
If you read up to this point you’re probably curious about the next articles. As you already know, the next step in our deployment pipeline would be the Docker image build and afterwards the actual deployment on our servers.
Things have changed since last year, in particular the Docker image build step has been integrated in the very first step: we not only publish our Spring Boot artifact, but also build and push our Docker image quite early. You can already see the necessary code in the example-backend Gradle script, but we’ll go into detail in the next article.
We’re glad about feedback, questions, and suggestions! So feel free to add a comment, add a pull request with improvements, or contact us via Twitter @gesellix!